AI-Powered Analysis¶
Champa Intelligence integrates Google Gemini AI to provide intelligent process analysis, root cause identification, and actionable recommendations.
Overview¶
The AI Analysis feature transforms complex process data into natural language insights, making it accessible to both technical and non-technical users.
Key Capabilities¶
- 🧠 Natural Language Insights - Understand process data without SQL
- 🔍 Root Cause Analysis - AI identifies patterns leading to incidents
- 📊 Multi-Process Comparison - Benchmark performance across definitions
- 🎯 Predictive Recommendations - Proactive optimization suggestions
- 🌍 Multi-Language Support - Reports in 11+ languages
- 📝 Analysis History - Save and revisit past analyses
- ⚡ Redis-Backed Caching - Lightning-fast repeat analyses
- 🔧 BPMN-Aware Analysis - Deep insights into process logic
How It Works¶
sequenceDiagram
participant User
participant Champa
participant Redis
participant Database
participant Gemini
User->>Champa: Request Analysis
Champa->>Redis: Check Cache
alt Cache Hit
Redis-->>Champa: Return Cached Data
else Cache Miss
Champa->>Database: Fetch Process Data
Database-->>Champa: Return Data
Champa->>Redis: Store in Cache
end
Champa->>Gemini: Send Prompt + Data
Gemini-->>Champa: AI Analysis
Champa->>User: Formatted Report
Champa->>Database: Save to HistoryData Collection:
- Parallel queries fetch 15+ data types (incidents, performance, variables, etc.)
- Results cached in Redis (1-24 hours TTL)
- Data summarized and structured for AI
AI Processing:
- Comprehensive prompt with focus-specific instructions
- Google Gemini generates analysis
- Response cleaned and formatted as HTML
Result Delivery:
- Markdown converted to HTML
- Displayed in browser
- Saved to history (optional)
Analysis Modes¶
Focus Areas¶
| Focus | Description | Data Analyzed | Best For |
|---|---|---|---|
| general | Holistic health assessment | Cross-cutting analysis from all areas | Management overview |
| incidents | Deep dive into errors | Incidents, error patterns, correlations, precursors | DevOps, Support |
| performance | Bottleneck detection | Activity durations, wait times, API calls, concurrency | Process Analysts |
| long_running | Stuck instance investigation | Stuck instances, event subscriptions, transaction durations | Operations |
| variables | Data quality & compliance | Variable sensitivity, data types, null values, PII detection | Data Governance |
| patterns | Process variant analysis | Execution paths, rework, DMN decisions | Business Analysts |
Detail Levels¶
Word Limit: 500 words
Content:
- Top 3 critical findings
- Immediate action items
- Risk summary
- No technical jargon
Best For:
- C-level executives
- Weekly reports
- Board presentations
Word Limit: 1,500 words
Content:
- 5-7 key findings
- Performance metrics
- Prioritized recommendations
- Some technical details
Best For:
- Process owners
- Team leads
- Monthly reviews
Word Limit: 3,000 words
Content:
- 10-15 detailed findings
- Full metrics breakdown
- Implementation guides
- BPMN element references
Best For:
- Developers
- Technical architects
- Root cause analysis
Using AI Analysis¶
Step 1: Navigate to AI Analysis¶
URL: /ai-analysis
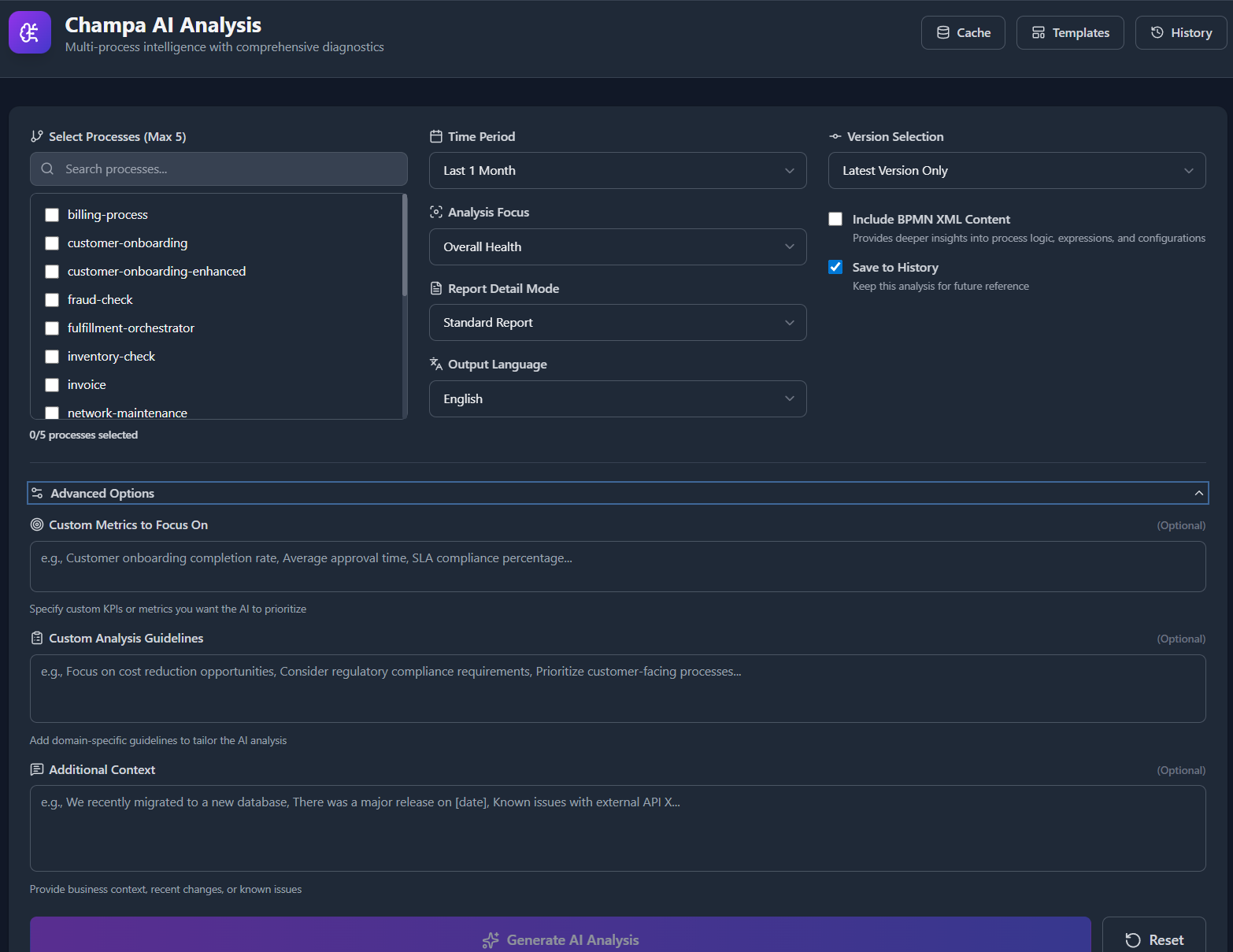
Step 2: Configure Analysis¶
Process Selection:
- Select 1-5 processes (max 5) - Multi-process enables benchmarkingVersion Mode:
- Latest: Most recent version only
- Last N: Analyze last 2-5 versions
- Specific: Choose exact versions
Time Range: - 1 week to 6 months - Recommended: 30 days for balanced insights
Step 3: Choose Focus & Detail¶
Analysis Focus:
- General (holistic overview)
- Incidents & Failures
- Performance & Bottlenecks
- Long-Running Processes
- Variables & Data Quality
- Execution Patterns
Report Detail:
- Executive Summary (500 words)
- Standard Report (1,500 words)
- Technical Deep-Dive (3,000 words)
Output Language:¶
- English (default), Spanish, French, German, Italian, Portuguese, Dutch, Polish, Ukrainian, Russian, Chinese, Japanese
Step 3: Advanced Options¶
Click Advanced Options to expand:
Custom Metrics¶
Define KPIs for AI to prioritize:
Custom Guidelines¶
Add domain-specific instructions:
Focus on cost reduction opportunities
Consider GDPR compliance requirements
Prioritize customer-facing processes
Additional Context¶
Provide business context:
Deployed v3 on Jan 10 with new payment gateway
Black Friday sale started Jan 12
Database upgraded to PostgreSQL 15 on Jan 8
Include BPMN XML¶
Enable to get deeper insights:
- ✅ Analyzes process flow logic and expressions
- ✅ Reviews script task complexity
- ✅ Examines error boundary events
- ✅ Identifies async continuation patterns
- ⚠️ Adds 5-15 seconds to processing time
- ⚠️ Increases token usage by 25-100%
Save to History¶
- ✅ Store for future reference
- ✅ Share via link with colleagues
- ✅ Export in multiple formats
Step 5: Generate Analysis¶
Click Generate AI Analysis and wait 10-60 seconds.
Processing Time Factors:
- Number of processes (1-5)
- Time range (7-180 days)
- BPMN XML inclusion
- Cache warmth (first run slower)
- Detail level
Step 6: Review Results¶
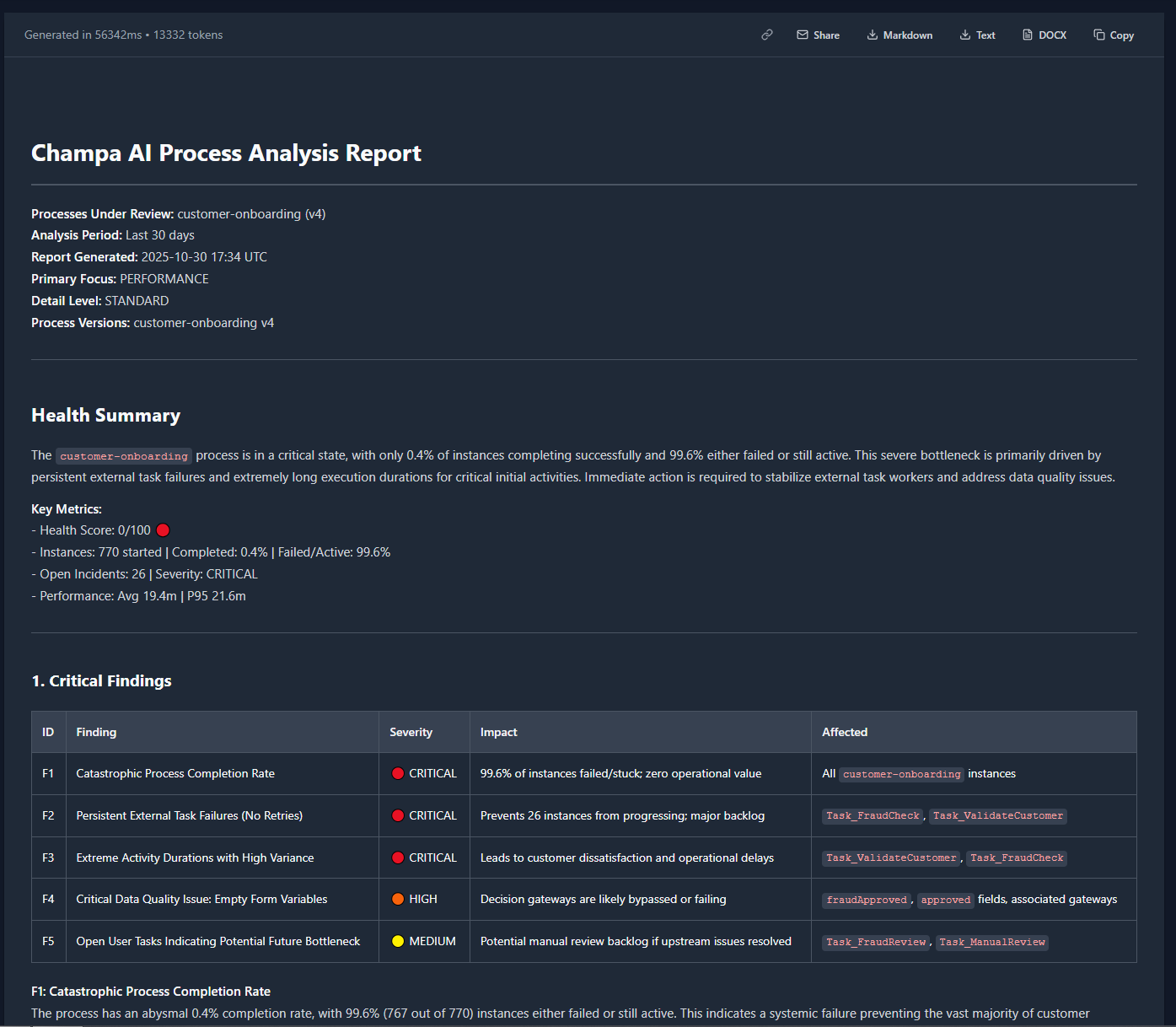
Report Structure¶
Every report follows this format:
# Champa AI Process Analysis Report
**Processes Under Review:** [List with versions]
**Analysis Period:** [Time range]
**Report Generated:** [Timestamp]
**Primary Focus:** [Focus area]
**Detail Level:** [Executive/Standard/Technical]
**Process Versions:** [Detailed list]
---
## Health Summary
[2-3 sentence overview with critical finding]
**Key Metrics:**
- Health Score: X/100 🟢/🟡/🟠/🔴
- Instances: [started] | Completed: [X%] | Failed/Active: [X%]
- Open Incidents: [count] | Severity: [level]
- Performance: Avg [duration] | P95 [duration]
---
[Main content sections based on focus]
Health Score Calculation¶
Components (0-100 scale):
- Success Rate (60% weight): completed / started × 100
- Failure Rate (30% weight): failed / started × 100
- Incident Impact (up to 50 points penalty): incident_count × 2
Thresholds:
- 🟢 80-100: Healthy - minor issues only
- 🟡 60-79: Needs Attention - some problems
- 🟠 40-59: Degraded - significant issues
- 🔴 0-39: Critical - immediate action required
Reading Tables¶
AI reports use extensive tables for efficiency:
Incident Table Example:
| ID | Finding | Severity | Impact | Affected |
|---|---|---|---|---|
| F1 | External API timeout | 🔴 CRITICAL | 120 instances (12%) | payment-gateway |
| F2 | Database deadlock | 🟠 HIGH | 45 instances (4.5%) | approval-service |
Performance Table Example:
| Activity | Avg | P95 | P99 | Executions |
|---|---|---|---|---|
| validate_payment | 2.3s | 5.1s | 12.4s | 1,245 |
| send_notification | 450ms | 1.2s | 3.8s | 3,402 |
Action Priorities¶
P1 (Immediate):
- Impact: HIGH/CRITICAL
- Effort: Usually LOW-MEDIUM
- Timeline: 1-3 days
- Example: Fix critical API timeout
P2 (Short-term):
- Impact: MEDIUM-HIGH
- Effort: MEDIUM
- Timeline: 1-2 weeks
- Example: Optimize slow database query
P3 (Medium-term):
- Impact: MEDIUM-LOW
- Effort: MEDIUM-HIGH
- Timeline: 1-3 months
- Example: Redesign process architecture
Report Actions¶
Export Options¶
Markdown (.md):
- Preserves formatting
- Compatible with GitHub, GitLab
- Easy to version control
Plain Text (.txt):
- Universal compatibility
- No formatting
- Fastest to load
Word Document (.docx):
- Professional reports
- Editable in Microsoft Word
- Preserves tables and formatting
Sharing¶
Copy Link:
- Generates permanent URL:
/ai-analysis?reportID=42 - Share with colleagues
- Link remains valid while report exists in history
Email Share:
- Opens default email client
- Pre-filled subject and body
- Includes report link
Copy to Clipboard:
- Copies plain text version
- Paste into emails, chats
- No formatting preserved
Analysis History¶
Managing History¶
Access via History button in header.
View:
- Last 20 analyses
- Sorted by creation date (newest first)
- Process config, focus, detail level shown
- One-click to reload
Search/Filter:
- Currently: chronological view only
- Future: filter by process, focus, date range
Delete:
- Per-user basis (can't see others' analyses)
- Confirmation required
- Permanent deletion
Export from History:
- Same options as current report
- Markdown, Text, DOCX
Sharing from History¶
Each history item has:
- 🔗 Link icon - Copy shareable URL
- 👁️ View - Load in main view
- 🗑️ Delete - Remove from history
Templates¶
Pre-configured analysis setups for common scenarios.
Available Templates¶
Incident Investigation:
{
"focus": "incidents",
"detail_level": "technical",
"duration": "1_week",
"include_bpmn_xml": true,
"custom_guidelines": "Identify root causes and provide step-by-step remediation"
}
Performance Optimization:
{
"focus": "performance",
"detail_level": "standard",
"duration": "1_month",
"custom_metrics": "Target: P95 < 10s, Avg < 3s"
}
Pre-Deployment Validation:
{
"version_mode": "specific",
"specific_versions": {"order-to-cash": [2, 3]},
"focus": "general",
"detail_level": "technical",
"custom_guidelines": "Compare v2 vs v3 for deployment readiness"
}
Compliance Audit:
{
"focus": "variables",
"detail_level": "standard",
"custom_guidelines": "Identify PII, PCI-DSS, and GDPR compliance risks"
}
Creating Custom Templates¶
Templates are defined in config_ai.py:
AI_ANALYSIS_TEMPLATES = [
{
"id": "custom_template",
"name": "My Custom Template",
"description": "Weekly operations review",
"focus": "general",
"detail_level": "standard",
"duration": "1_week",
"include_bpmn_xml": False,
"custom_guidelines": "Focus on operational KPIs"
}
]
Cache Management¶
Viewing Cache Stats¶
Click Cache button to see:
Summary:
- Total cached entries across all types
- Redis connection status
- Number of cache types (14)
Per-Type Breakdown:
- Cache name (e.g., "Incident Stats")
- Redis key prefix (e.g.,
ai:incident) - Number of cached keys
- TTL in seconds
Operations¶
Refresh Stats:
- Reload cache statistics
- See current state
- No impact on cache data
Clear All Caches:
- ⚠️ Requires confirmation
- Clears all 14 cache types
- Next analysis will be slower (cache rebuild)
- Use when: Data seems stale or incorrect
When to Clear:
- After major database changes
- When seeing outdated results
- After Camunda version upgrade
- When troubleshooting inconsistencies
AI Model Settings¶
File: config_ai.py
# Model Configuration
AI_MODEL_NAME = 'gemini-2.0-flash-exp'
AI_TEMPERATURE = 0.3 # Lower = more factual, higher = creative
AI_TOP_P = 0.95 # Nucleus sampling threshold
AI_TOP_K = 40 # Top-K sampling
# Response Format
AI_RESPONSE_MODALITIES = ["TEXT"]
# Word Limits by Detail Level
AI_WORD_LIMITS = {
'executive': 500,
'standard': 1500,
'detailed': 3000
}
# Data Collection
AI_MAX_XML_SECTION_CHARS = 50000 # BPMN XML size limit
AI_DATA_SUMMARY_MAX_CHARS = 100000 # Total prompt data limit
# Performance
AI_PARALLEL_DATA_FETCH_ENABLED = True
AI_PARALLEL_DB_MAX_WORKERS = 5
# Templates
AI_ENABLE_ANALYSIS_TEMPLATES = True
AI_ANALYSIS_TEMPLATES = [...]
Cache Behavior Without Redis:
- Falls back to in-memory caching
- Cache not shared across workers
- Statistics unavailable
- Slower performance
Database Query Tuning¶
Queries use indexes on: - act_hi_procinst: proc_def_id_, start_time_ - act_hi_incident: proc_def_id_, create_time_ - act_hi_actinst: proc_inst_id_, start_time_ - act_re_procdef: key_, version_
Recommended Indexes:
CREATE INDEX idx_hi_procinst_proc_def_start
ON act_hi_procinst(proc_def_id_, start_time_);
CREATE INDEX idx_hi_incident_proc_def_create
ON act_hi_incident(proc_def_id_, create_time_);
CREATE INDEX idx_hi_actinst_proc_inst_start
ON act_hi_actinst(proc_inst_id_, start_time_);
API Usage¶
Generate Analysis¶
Request:
{
"processes": ["order-to-cash", "invoice-processing"],
"version_mode": "latest",
"version_count": 1,
"specific_versions": {},
"duration": "1_month",
"focus": "incidents",
"detail_level": "standard",
"include_bpmn_xml": true,
"output_language": "en",
"custom_guidelines": "Focus on customer-facing issues",
"additional_context": "Recent deployment on Jan 15",
"custom_metrics": "SLA: 5s response time",
"save_history": true
}
Response:
{
"analysis": "<h1>Champa AI Process Analysis Report</h1>...",
"analysis_id": 42,
"metadata": {
"duration_ms": 12450,
"estimated_tokens": 8500
}
}
Get Analysis History¶
Response:
[
{
"id": 42,
"process_config": {"order-to-cash": [3]},
"focus": "incidents",
"detail_level": "standard",
"days_back": 30,
"options": {
"include_bpmn_xml": true,
"output_language": "en"
},
"created_at": "2025-01-15T10:30:00"
}
]
Get Specific Analysis¶
Response:
{
"id": 42,
"analysis_content": "# Report...",
"analysis_html": "<h1>Report...</h1>",
"...": "..."
}
Export Analysis¶
Formats: md, txt
Response: File download
Best Practices¶
🎯 Optimize Token Usage¶
- Start with executive level to get overview
- Use standard for most analyses - best balance
- Technical only when needed for deep dives
- Disable BPMN XML for faster, cheaper results
📊 Effective Prompting¶
Good Custom Guidelines:
- ✅ Focus on activities with >100ms avg duration
- ✅ Prioritize incidents affecting payment flow
- ✅ Compare performance between US and EU regions
- ✅ Identify data quality issues in customer data
Poor Custom Guidelines:
- ❌ "Make it better"
- ❌ "Fix all problems"
- ❌ "Tell me everything"
🔍 Context Matters¶
Include relevant context:
- Recent deployments
- Infrastructure changes
- Known issues
- Business events (holidays, campaigns)
Example:
Deployed v4 on Jan 10 with new payment gateway.
Black Friday sale started Jan 12.
Database upgraded to PostgreSQL 15 on Jan 8.
Known issue: External API X times out during peak
⚡ Performance Tips¶
For Fastest Results:
- Select 1-2 processes (not 5)
- Use 30-day window (not 6 months)
- Disable BPMN XML
- Use executive or standard level
- Wait for cache to warm up
For Comprehensive Analysis:
- Select all relevant processes
- Use 90-day window for trends
- Enable BPMN XML
- Use technical level
- Schedule during off-peak hours
Cache Warming:
- First analysis: 30-60s
- Cached analysis: 10-15s
- Cache hit rate: typically 80%+ after warmup
Supported Languages¶
| Language | Code | Sample Output |
|---|---|---|
| English | en | "The process has 23 open incidents..." |
| Spanish | es | "El proceso tiene 23 incidentes abiertos..." |
| German | de | "Der Prozess hat 23 offene Vorfälle..." |
| French | fr | "Le processus a 23 incidents ouverts..." |
| Italian | it | "Il processo ha 23 incidenti aperti..." |
| Portuguese | pt | "O processo tem 23 incidentes abertos..." |
| Dutch | nl | "Het proces heeft 23 openstaande incidenten..." |
| Polish | pl | "Proces ma 23 otwarte incydenty..." |
| Ukrainian | uk | "Процес має 23 відкритих інцидентів..." |
| Russian | ru | "У процесса 23 открытых инцидента..." |
| Chinese | zh | "该流程有 23 个未解决的事件..." |
| Japanese | ja | "プロセスには23の未解決のインシデントがあります..." |
Translation Quality
Technical terms (BPMN element IDs, variable names) remain in English for accuracy.
Troubleshooting¶
"AI features are not configured"¶
Cause: Missing or invalid Google API key
Solution:
# Check environment variable
echo $GOOGLE_API_KEY
# Test API key
curl -H "Content-Type: application/json" \
-d '{"contents":[{"parts":[{"text":"Hello"}]}]}' \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-2.0-flash-exp:generateContent?key=$GOOGLE_API_KEY"
Analysis Takes Too Long¶
Causes:
- Large BPMN XML files
- Many processes selected
- Long time ranges
- Uncached data
- Database performance issues
Solutions:
- Disable BPMN XML inclusion
- Reduce number of processes
- Shorten time range to 30 days
- Run once to warm cache
- Database tuning, e.g. adding of appropriate indexes
Empty or Generic Responses¶
Causes:
- No data in selected time range
- Insufficient incidents/activity
- API rate limiting
- Unclear custom guidelines
Solutions: 1. Extend time range 2. Check process has data in selected period 3. Verify API quota 4. Review custom guidelines for clarity
Cost Optimization¶
Token Usage Estimates¶
| Detail Level | Avg Input Tokens | Avg Output Tokens | Total |
|---|---|---|---|
| Executive | 15,000 | 700 | ~15,700 |
| Standard | 20,000 | 2,000 | ~22,000 |
| Technical | 30,000 | 4,000 | ~34,000 |
With BPMN XML: +5,000 to +30,000 tokens
Cost Reduction Strategies¶
- Use caching - Reduce API calls by 80%+
- Batch analyses - Process multiple at once
- Executive summaries - Then drill down if needed
- Disable XML - Save 25-40% tokens
- Shorter time ranges - 30 days vs 90 days
Monitoring Usage¶
# Track token usage
from utils.logger import get_logger
ai_logger = get_logger('champa.ai')
# Logged automatically on each analysis
# Check logs/ai.log for usage patterns
Security & Privacy¶
We take data security seriously. All data sent to the AI is strictly sanitized to remove PII and commercial secrets. For full details, see our Zero Trust Security Report.
Data Handling¶
What gets sent to Google Gemini:
- ✅ Process statistics (counts, averages, percentiles)
- ✅ Incident types and activity IDs
- ✅ BPMN XML structure (if enabled)
- ✅ Error message patterns
Is not sent:
- ❌ Business keys
- ❌ Variable values (except data types)
- ❌ User identities
- ❌ Customer data
Data Protection:
- PII automatically masked before sending
- Variable values excluded from prompts
- Only metadata and statistics sent
- API calls over HTTPS
- No data stored by Google (per Gemini API terms)
Compliance¶
GDPR Compliance:
- No personal data in AI prompts
- Analysis history stored in your database
- User can delete their analysis history
- Audit trail for all AI operations
Access Control:
- Requires
ai_analysis_datapermission - Analysis history per-user
- Admin can't see other users' analyses
Next Steps¶
- API Reference - Complete API documentation
- Configuration - Configure AI settings
- Process Intelligence - Explore data dashboard
- Admin Guide - Manage user permissions