Portfolio Dashboard¶
 Executive command center for monitoring all process definitions at scale
Executive command center for monitoring all process definitions at scale
Overview¶
The Portfolio Dashboard is your strategic command center for managing and monitoring your entire Camunda process landscape. Unlike feature-specific views that focus on individual processes or instances, the Portfolio Dashboard provides a bird's-eye view of your complete BPM ecosystem, enabling executives, operations managers, and process owners to understand portfolio-wide health, identify critical issues instantly, and track performance trends over time.
The Challenge: Managing Process Portfolios at Scale¶
Organizations running Camunda in production typically manage dozens or hundreds of process definitions across multiple versions, environments, and business domains. Without portfolio-level visibility, teams face:
- ❌ No unified view - Must check each process individually to understand overall health
- ❌ Reactive firefighting - Discover critical issues only after escalation
- ❌ Resource inefficiency - Can't identify where to focus optimization efforts
- ❌ Blind spot on trends - Miss patterns that indicate systemic problems
- ❌ Lack of executive metrics - No way to report business velocity and operational excellence
The Portfolio Dashboard solves these problems by aggregating, analyzing, and visualizing metrics across your entire process portfolio in a single, actionable interface.
Key Capabilities¶
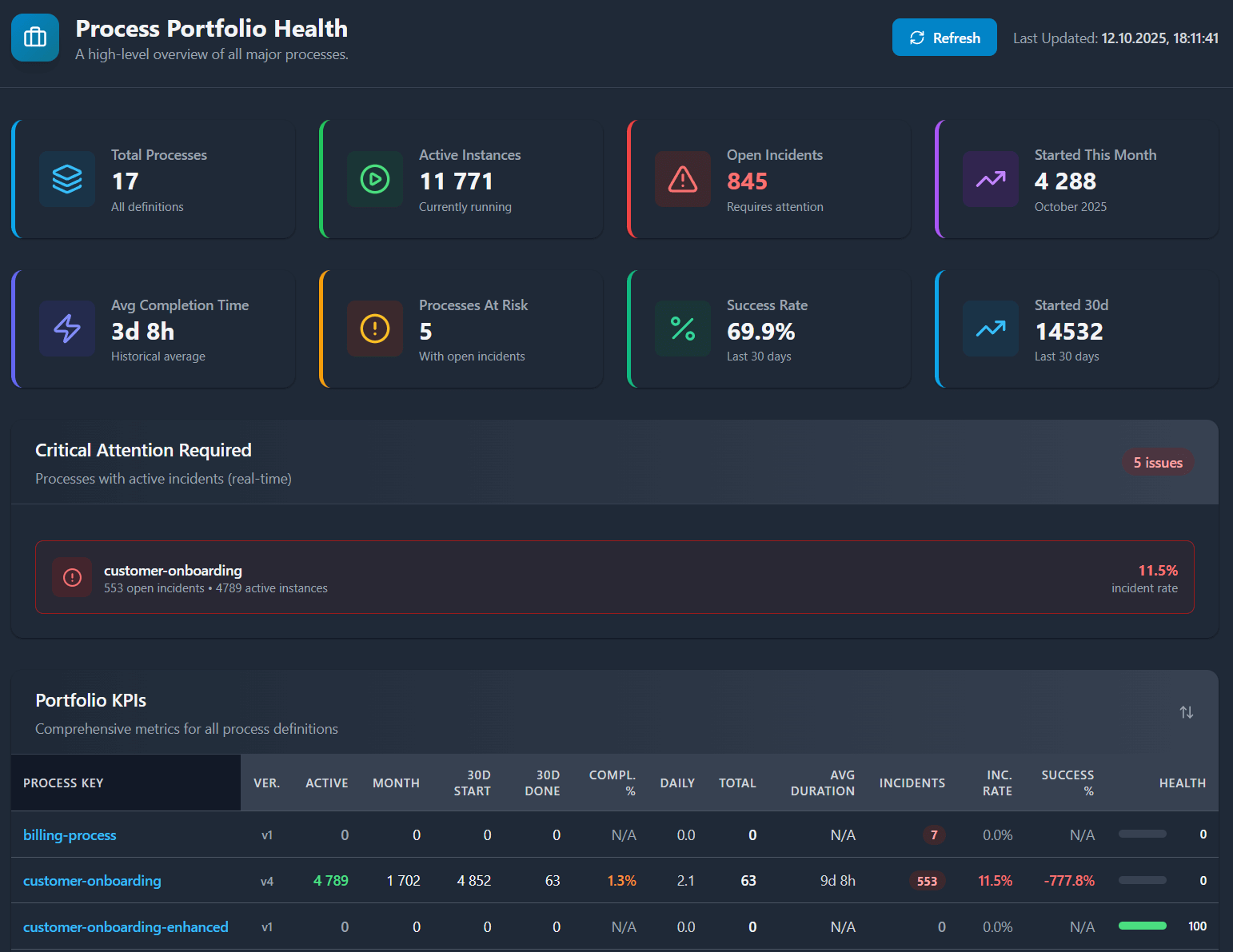
📊 At-a-Glance Executive KPIs¶
Eight critical metrics provide instant understanding of portfolio health:
Operational Metrics:
- Total Processes - Number of unique process definitions being monitored
- Active Instances - Real-time count of currently running process instances across all definitions
- Open Incidents - Total unresolved incidents indicating immediate operational issues
- Started This Month - New instances launched in the current calendar month
Business Velocity:
- Started 30d - Instances started in the last 30 days (throughput indicator)
- Success Rate - Percentage of instances completed without incidents in last 30 days (quality metric)
- Avg Completion Time - Historical average duration across all completed instances (efficiency benchmark)
- Processes At Risk - Count of process definitions with one or more open incidents (risk exposure)
These KPIs answer the fundamental questions:
- How much work are we processing? (Active Instances, Started metrics)
- How well are we performing? (Success Rate, Completion Time)
- What needs immediate attention? (Open Incidents, Processes At Risk)
🚨 Critical Attention Module¶
The "Critical Attention Required" section automatically identifies the top 5 most problematic processes based on a weighted score combining:
- Incident count - Absolute number of open incidents
- Incident rate - Percentage of active instances with incidents
This intelligent prioritization ensures teams focus optimization efforts where they'll have the greatest impact. Each entry shows:
- Process key (clickable to Journey Monitoring)
- Number of open incidents
- Number of active instances
- Incident rate percentage
Empty state: When no incidents exist, displays "All Systems Operational" with green checkmark—instant confidence for stakeholders.
📈 Portfolio KPIs Table¶
Comprehensive metrics table for every process definition in your portfolio:
| Metric | Description | Use Case |
|---|---|---|
| Process Key | Definition identifier (clickable) | Navigate to details |
| Ver. | Latest version number | Version tracking |
| Active | Currently running instances | Real-time workload |
| Month | Started this month | Current month activity |
| 30d Start | Started last 30 days | Recent throughput |
| 30d Done | Completed last 30 days | Completion throughput |
| Compl. % | Completion rate (Done/Start × 100) | Process efficiency |
| Daily | Average completions per day | Steady-state capacity |
| Total | All-time completed instances | Historical volume |
| Avg Duration | Mean completion time | Performance baseline |
| Incidents | Current open incidents | Real-time problems |
| Inc. Rate | Incidents/Active × 100 | Problem density |
| Success % | Completed without incidents (30d) | Quality metric |
| Health | Composite health score (0-100) | Overall status |
🔍 Process Health Matrix¶
Visual grid providing rapid health assessment of all processes:
Three Health States:
🟢 Healthy (Green)
- No open incidents
- Has active instances
- Operating normally
⚪ Idle (Gray)
- No open incidents
- Zero active instances
- Recently inactive
🔴 Incidents (Red)
- One or more open incidents
- Requires attention
Each tile shows:
- Process key
- Health status indicator
- Active instances count
- Instances started this month
Use Case: Quickly scan the portfolio to identify patterns (e.g., "Why are 5 processes idle?" or "Which healthy processes need capacity planning?")
📉 12-Month Trend Analysis¶
Interactive ApexCharts line chart plotting historical trends:
Dual Metrics:
- Blue Line: Instances Started per month
- Red Line: Incidents Created per month
Insights Enabled:
- Seasonal Patterns - Identify monthly workload variations (e.g., month-end spikes)
- Trend Detection - Spot increasing incident rates over time
- Release Impact - Correlate deployments with stability changes
- Capacity Planning - Forecast based on growth trends
- Performance Degradation - Catch declining quality before crisis
Interactive Controls:
- Hover to see exact values
- Legend toggle to focus on single metric
- Responsive to dark mode theme changes
🔄 Auto-Loading Architecture¶
The dashboard uses intelligent lazy loading to optimize performance:
Initial Page Load:
- Renders shell immediately
- Shows loading skeletons for data sections
- No blocking database queries
Progressive Loading:
- Overview data loads when summary cards enter viewport
- Trends data loads when chart section enters viewport
- Refresh button reloads all data on-demand
Benefits:
- Fast perceived performance - Page appears instantly
- Reduced server load - Only loads data when viewed
- Responsive updates - Refresh specific sections independently
Understanding the Metrics¶
Time Scopes Explained¶
The dashboard uses three distinct time windows for different purposes:
Real-Time (Current Moment)
- Active Instances
- Open Incidents
- Incident Rate
- Health Score
These reflect right now - the live state of your portfolio.
Last 30 Days (Rolling Window)
- Started 30d
- Completed 30d
- Completion Rate
- Success Rate
These track recent performance - how well you've been doing lately.
Current Month (Calendar Month)
- Started This Month
Tracks this month's activity - useful for monthly reporting.
All-Time (Historical)
- Total Completed
- Average Duration
Provides long-term context - your complete history.
Calculated Metrics¶
Completion Rate
Values below 80% indicate backlog buildup.Success Rate
Target: Above 95% for production-grade processes.Incident Rate
Any value above 5% warrants investigation.Throughput (Daily)
Measures steady-state capacity.Health Score
Composite metric factoring incidents and activity. Range: 0-100.Using the Portfolio Dashboard¶
For Executives¶
Morning Check (2 minutes):
- Open Portfolio Dashboard
- Review KPI cards at top
- Check "Critical Attention Required" section
- If all green → Review "Processes At Risk" count
- If issues exist → Delegate to operations team with process keys
Key Questions Answered:
- Is our BPM platform healthy overall?
- How much business are we processing?
- Are we meeting quality targets?
- Where should we invest improvement efforts?
For Operations Managers¶
Daily Workflow:
-
Morning Standup Prep
-
Review "Critical Attention Required"
- Note top 3 processes by incident count
-
Check Success Rate trend
-
Incident Triage
-
Click processes with incidents
- Navigate to Journey Monitoring for root cause
-
Assign fixes to team
-
Capacity Planning
-
Review "Throughput" column
- Compare "Active" to historical baseline
-
Identify processes approaching capacity
-
Trend Analysis
-
Check 12-month chart weekly
- Look for degrading trends
- Correlate with deployments
For Process Owners¶
Weekly Review:
-
Find Your Processes
-
Scan KPIs table for your process keys
-
Sort by "Health" to find issues
-
Performance Assessment
-
Compare "Avg Duration" to target SLAs
- Check "Success Rate" against goal (typically 95%+)
-
Review "Completion Rate" for efficiency
-
Optimization Opportunities
-
Low "Daily Throughput" + High "Active Instances" = Bottleneck
- High "Avg Duration" = Optimization candidate
- Low "Completion Rate" = Investigation needed
For SRE/DevOps Teams¶
Integration Scenarios:
Prometheus/Grafana:
# Scrape portfolio metrics
prometheus.yml:
scrape_configs:
- job_name: 'camunda-portfolio'
static_configs:
- targets: ['champa:5000']
metrics_path: '/portfolio/overview/metrics'
scrape_interval: 5m
Alerting Rules:
# Grafana alert rules
- alert: HighIncidentRate
expr: camunda_process_incident_rate > 10
annotations:
summary: "Process {{ $labels.process }} has high incident rate"
- alert: ProcessAtRisk
expr: camunda_portfolio_processes_at_risk > 3
annotations:
summary: "Multiple processes require attention"
Dashboard Integration: Create Grafana dashboard combining Portfolio metrics with infrastructure metrics for correlation analysis.
Prometheus Integration¶
All Portfolio KPIs are exposed via Prometheus endpoint: /portfolio/overview/metrics
Available Metrics¶
Portfolio-Level Aggregates:
# Portfolio-wide totals
camunda_portfolio_total_processes
camunda_portfolio_active_instances
camunda_portfolio_open_incidents
camunda_portfolio_started_last_30_days
camunda_portfolio_completed_last_30_days
camunda_portfolio_processes_at_risk
Per-Process Metrics:
# Labels: process, version
camunda_process_active_instances{process="order-fulfillment",version="3"}
camunda_process_open_incidents{process="order-fulfillment",version="3"}
camunda_process_started_last_30_days{process="order-fulfillment",version="3"}
camunda_process_completed_last_30_days{process="order-fulfillment",version="3"}
camunda_process_started_this_month{process="order-fulfillment",version="3"}
camunda_process_success_rate_30d{process="order-fulfillment",version="3"}
camunda_process_health_score{process="order-fulfillment",version="3"}
camunda_process_incident_rate{process="order-fulfillment",version="3"}
camunda_process_avg_duration_seconds{process="order-fulfillment",version="3"}
camunda_process_total_completed_all_time{process="order-fulfillment",version="3"}
camunda_process_completion_rate_30d{process="order-fulfillment",version="3"}
camunda_process_throughput_30d{process="order-fulfillment",version="3"}
Example PromQL Queries¶
Portfolio Health Check:
# Alert when portfolio has critical incident load
camunda_portfolio_open_incidents > 50
# Alert when too many processes at risk
camunda_portfolio_processes_at_risk > 5
# Portfolio-wide success rate
100 * (
camunda_portfolio_completed_last_30_days -
sum(camunda_process_open_incidents)
) / camunda_portfolio_completed_last_30_days
Process Performance:
# Top 5 processes by incident rate
topk(5, camunda_process_incident_rate)
# Processes with declining health
camunda_process_health_score < 60
# Average completion time across portfolio
avg(camunda_process_avg_duration_seconds)
# Throughput leaders
topk(10, camunda_process_throughput_30d)
Capacity & Load:
# Portfolio-wide capacity utilization
sum(camunda_process_active_instances) /
sum(camunda_process_throughput_30d * 30)
# Processes nearing capacity
camunda_process_active_instances /
camunda_process_throughput_30d > 10
Common Patterns & Use Cases¶
Pattern 1: Morning Health Check¶
Scenario: Daily standup prep
Workflow:
- Open Portfolio Dashboard
- Check "Open Incidents" KPI
- If 0 → "All clear, team!"
- If >0 → Review "Critical Attention Required"
- Note top 3 problem processes
- Click process key → Navigate to details
- Assign incidents to team members
Time: 2-3 minutes
Pattern 2: Capacity Planning¶
Scenario: Quarterly capacity review
Workflow:
- Review "12-Month Trend" chart
- Identify growth rate in instances started
- Calculate projected growth:
- Current: 10,000/month
- Growth: +15%/quarter
- Projection: 11,500/month next quarter
- Check "Active Instances" across all processes
- Compare to infrastructure capacity
- Plan scaling if projected load exceeds 80% capacity
Time: 15 minutes
Pattern 3: Release Impact Analysis¶
Scenario: Post-deployment validation
Workflow:
- Note date of deployment
- Check "Success Rate" before vs after
- Review "12-Month Trend" for incident spike
- Check specific deployed process in KPIs table
- If incident rate increased → Rollback or hotfix
Decision Point: - Success Rate dropped >5% → Investigate immediately - Incident Rate >10% on new process → Consider rollback
Time: 5 minutes
Pattern 4: Executive Reporting¶
Scenario: Monthly board report
Workflow:
- Export Prometheus metrics to spreadsheet
- Calculate month-over-month changes:
- Instances processed: +12%
- Success rate: 96.5% (target: 95%)
- Processes at risk: 2 (down from 5)
- Avg completion time: 2.3 hours (improved from 2.8)
- Create PowerPoint slides with trend chart
- Highlight achievements and areas of concern
Time: 30 minutes monthly
Pattern 5: Process Portfolio Rationalization¶
Scenario: Annual process review
Workflow:
- Sort KPIs table by "Active Instances" ascending
- Identify processes with 0 active for 30+ days
- Check "Total Completed" to confirm legacy status
- Review "Health Matrix" for idle processes
- Propose decommissioning candidates
- Document business justification for remaining idle processes
Criteria for Decommissioning:
- Zero active instances for 90 days
- Low total completed (< 100)
- No future business need
- Replaced by newer process
Time: 2-4 hours annually
Troubleshooting¶
Issue: KPI Cards Show "Loading" Forever¶
Symptoms: Cards display skeleton animation indefinitely
Causes:
- Database connectivity issue
- Authentication token expired
- API endpoint returning error
Solutions:
- Open browser developer console (F12)
- Check Network tab for failed requests
- Check Console tab for JavaScript errors
- Refresh page (Ctrl+R)
- Verify authentication status
- Contact administrator if issue persists
Issue: Metrics Seem Outdated¶
Symptoms: Numbers don't match current reality
Causes:
- Looking at cached data (5-minute TTL)
- Recent incident not yet reflected
Solutions:
- Wait 5 minutes for cache to expire
- Click "Refresh" button to reload
- Check "Last Updated" timestamp
- Verify database replication lag (distributed systems)
Issue: Health Matrix Shows Everything as Idle¶
Symptoms: All processes gray despite activity
Causes:
- Database query issue
- Timezone mismatch
- No recent process starts
Solutions:
- Check "Active Instances" in KPI cards (should be >0)
- Verify instances are actually running in Camunda Cockpit
- Check database query filters for time zones
- Review process deployment status
Issue: Chart Not Rendering¶
Symptoms: Empty space where chart should be
Causes:
- JavaScript error
- No trend data available
- Dark mode rendering bug
Solutions:
- Check browser console for errors
- Verify at least 1 month of historical data exists
- Try toggling dark mode
- Disable browser extensions
- Try different browser
Best Practices¶
Dashboard Review Cadence¶
Daily (5 minutes):
- Check "Open Incidents" count
- Review "Critical Attention Required"
- Triage any red-flagged processes
Weekly (15 minutes):
- Scan entire KPIs table for anomalies
- Review "Success Rate" trends
- Check "Health Matrix" for new idle processes
- Note any declining health scores
Monthly (1 hour):
- Analyze "12-Month Trend" chart
- Calculate month-over-month metrics
- Review capacity projections
- Generate executive report
Quarterly (4 hours):
- Full portfolio health assessment
- Process rationalization review
- Capacity planning
- SLA compliance review
Metric Interpretation¶
Success Rate:
- 98-100%: Excellent
- 95-97%: Good (target range)
- 90-94%: Acceptable but monitor
- <90%: Investigation required
Incident Rate:
- 0-2%: Healthy
- 2-5%: Acceptable
- 5-10%: Monitor closely
-
10%: Critical - immediate action
Health Score:
- 90-100: Excellent health
- 70-89: Good, minor issues
- 50-69: Fair, attention needed
- <50: Poor, critical issues
Completion Rate:
- 90-100%: Normal
- 70-89%: Backlog building
- 50-69%: Significant backlog
- <50%: Capacity crisis
Alerting Thresholds¶
Critical (Immediate Response):
- Open Incidents > 50
- Processes At Risk > 5
- Any process Incident Rate > 20%
- Portfolio Success Rate < 90%
Warning (Within 24 Hours):
- Processes At Risk > 2
- Any process Incident Rate > 10%
- Any process Health Score < 50
- Completion Rate < 80%
Info (Weekly Review):
- Any process idle >7 days
- Success Rate declined >2% week-over-week
- Throughput increased >50% week-over-week
API Reference¶
REST Endpoints¶
| Endpoint | Method | Description |
|---|---|---|
/portfolio | GET | Portfolio dashboard page |
/portfolio/api/overview | GET | KPIs and process metrics (JSON) |
/portfolio/api/trends | GET | 12-month trend data (JSON) |
/portfolio/overview/metrics | GET | Prometheus metrics (text) |
JSON Response Format¶
Overview API:
{
"success": true,
"overview": [
{
"process_key": "order-fulfillment",
"latest_version": 3,
"total_completed_all_time": 15420,
"avg_duration_seconds": 8640,
"started_last_30_days": 892,
"completed_last_30_days": 845,
"started_this_month": 312,
"active_instances": 47,
"open_incidents": 2,
"success_rate_30d": 97.5,
"health_score": 85,
"incident_rate": 4.3
}
],
"summary_stats": {
"total_processes": 43,
"active_instances": 1234,
"open_incidents": 12,
"started_this_month": 5678,
"started_last_30_days": 8901,
"completed_last_30_days": 8234,
"processes_at_risk": 5,
"avg_completion_time": 7200,
"success_rate_30d": 96.2
},
"top_issues": [...],
"timestamp": "2025-11-01T10:30:00Z"
}
FAQ¶
Q: How often does the dashboard update?
A: Data refreshes every 5 minutes automatically via caching. Click "Refresh" button for immediate update.
Q: Can I export the KPI table?
A: Not directly in the UI. Use Prometheus metrics endpoint and export to CSV, or copy-paste from table.
Q: What's the difference between "Started This Month" and "Started 30d"?
A: "This Month" uses calendar month (resets monthly). "30d" is rolling 30-day window (more consistent for trends).
Q: Why is Success Rate different from (100% - Incident Rate)?
A: Success Rate = completed without incidents (quality). Incident Rate = active with incidents (current problems). Different denominators.
Q: Can I filter to specific processes?
A: Not currently. Workaround: Use browser search (Ctrl+F) to find process in table, or use Prometheus metrics with PromQL filters.
Q: What causes Health Score to be low with no incidents?
A: Process might be "Recently active but now idle" (penalty of 20 points). Indicates potential issue even without open incidents.
Q: How do I track improvement over time?
A: Use Prometheus integration to store metrics in time-series database, then create Grafana dashboards showing trends.
Q: Can multiple teams use different Portfolio views?
A: Not currently. All users see same portfolio. Recommendation: Use Grafana with filtered views per team.
Summary¶
The Portfolio Dashboard transforms BPM operations from reactive firefighting to proactive management:
✅ Unified visibility across entire process landscape
✅ Intelligent prioritization of issues requiring attention
✅ Executive-ready KPIs for business reporting
✅ Trend analysis for strategic planning
✅ Prometheus integration for enterprise monitoring
✅ Performance-optimized with smart caching
By providing the right metrics at the right level of detail, the Portfolio Dashboard enables informed decision-making and operational excellence at scale.